 Fraunhofer-Institut für Produktionstechnologie IPT
Fraunhofer-Institut für Produktionstechnologie IPTReine Kopfsache? KI im Bundesliga-Tippspiel-Experiment
Im Technologiemanagement gehen wir technologischen Trends auf den Grund und setzen uns wissenschaftlich mit ihnen auseinander. Aber als dieses Mal das jährliche Bundesliga-Tippspiel anstand, wählten wir einen anderen Ansatz: Wir wollten wissen, ob ein KI-Sprachmodell wie ChatGPT sich mit menschlichen Fußball-Expertinnen und -Experten messen kann. Das Experiment hat uns nicht nur überraschende Einblicke in die Fähigkeiten von ChatGPT gewährt, sondern auch Anhaltspunkte für wichtige Fragen zum KI-Einsatz im Technologiemanagement geliefert.
Das Bundesliga-Tippspiel hat in unserer Abteilung Tradition. Und so kam auch im August 2023 wieder die Aufforderung in unsere Chat-Runde:
Während vor dem Saisonstart abteilungsintern schon fleißig spekuliert wurde, wer sich dieses Mal als Tippkönig durchsetzen könnte, brachte jemand aus der Runde das gerade heiß diskutierte ChatGPT ins Spiel: Ein erster Anlauf von Tim förderte ohne konkrete Daten zur aktuellen Saison nur wenig überzeugende Ergebnisse zutage. Scharfsinnig bemerkte ich direkt:

Und lieferte, testweise, mal eben diese:
Auch wenn »eine variable Performance« eine schöne, vielleicht schon fast euphemistische Beschreibung der historischen Stuttgarter Spiel-Performance ist, wäre es etwas konkreter für ein Tippspiel doch besser:
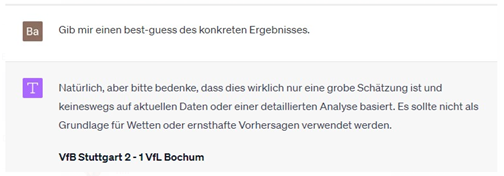
Die Kollegen waren begrenzt beeindruckt:

Aber wir werden sehen ...
Kalibrierung: Die Wahrheit liegt auf dem Platz
Damit war der Plan gefasst, zumindest so lange bis mir die Lust ausgeht, mit einem zweiten Account teilzunehmen – bespielt von ChatGPT. Der erste kritische Schritt: Für ChatGPT die Teilnahmegebühr bezahlen. Auch bei intensivem Zureden wollte es das selbst nicht übernehmen, aber ich streckte vor.
Der zweite, vermutlich wichtigere Schritt: Da ChatGPT einige wichtige Informationen fehlten – vor allem zeitnahe Daten zu aktueller Performance und Spielpaarungen – gab ich ChatGPT alles, was ich unkompliziert aus dem Internet selbst unformatiert kopieren und einfügen konnte: die aktuelle Tabelle, Paarungen und Wettquoten. Das Large Language Modell sollte schließlich zeigen, was es kann. So bekam es alle Informationen in der Rohform, wie ich sie im Internet finden konnte, ausschließlich mit den nötigsten Prompts zur Einordung. Ausgestattet mit diesen Informationen, lieferte ChatGPT auch prompt die Prognosen für den ersten Spieltag. Die Begründungen waren zwar etwas flach, für den Start aber auf jeden Fall ausreichend.
Saisonstart: ChatGPT läuft sich warm
Über mangelnde Performance konnte man sich nach sechs Spieltagen nicht beschweren: Nach anfänglich durchschnittlicher Performance setzte sich ChatGPT ab dem vierten Spieltag erstmals vom Mittelwert ab und mit dem fünften Spieltag an die Spitze des zwölfköpfigen Tippspiel-Teams.
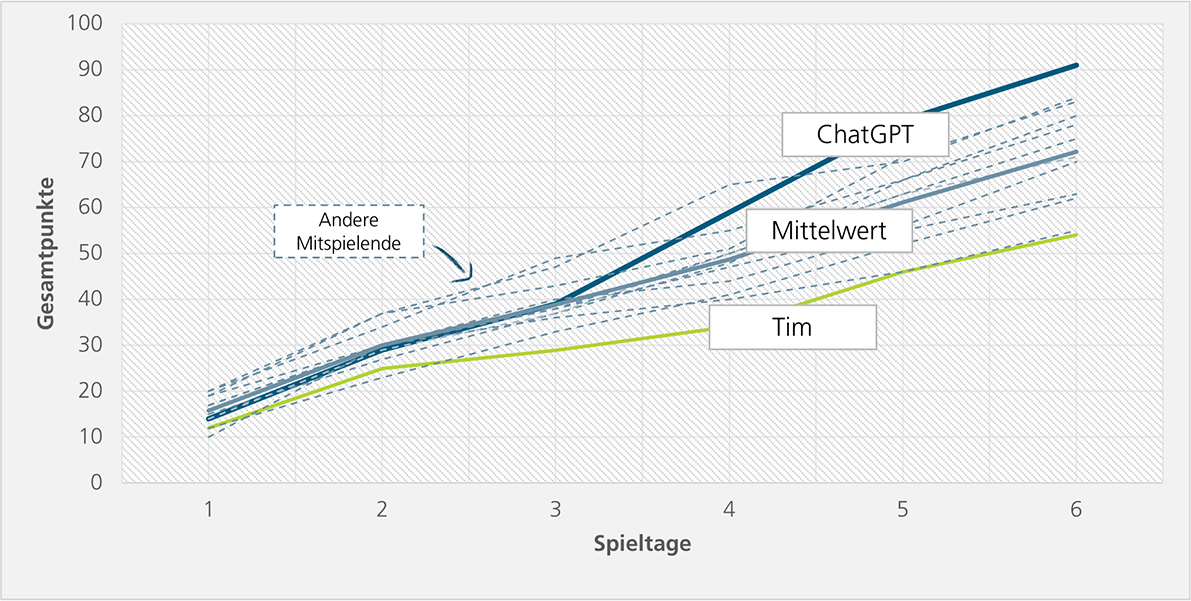
Langsam stellte sich auch bei hartnäckigen Zweiflern ein gewisser Respekt ein, selbst wenn die Begründungen der Tipps noch nicht überzeugten.
Zwischenbilanz: Nach nur sechs Spieltagen setzte sich ChatGPT an die Spitze. War das nur Zufall? Wirklich empirisch belastbar war der Versuch wohl kaum, fortgesetzt wurde er dennoch.
Glorreich in die Winterpause: ChatGPT bleibt am Ball
Als Ergebnis des fulminanten Starts waren wir neugierig geworden. Daher ging die Saison für ChatGPT weiter – und präsentierte sich nach 17 Spieltagen immer noch überlegen:
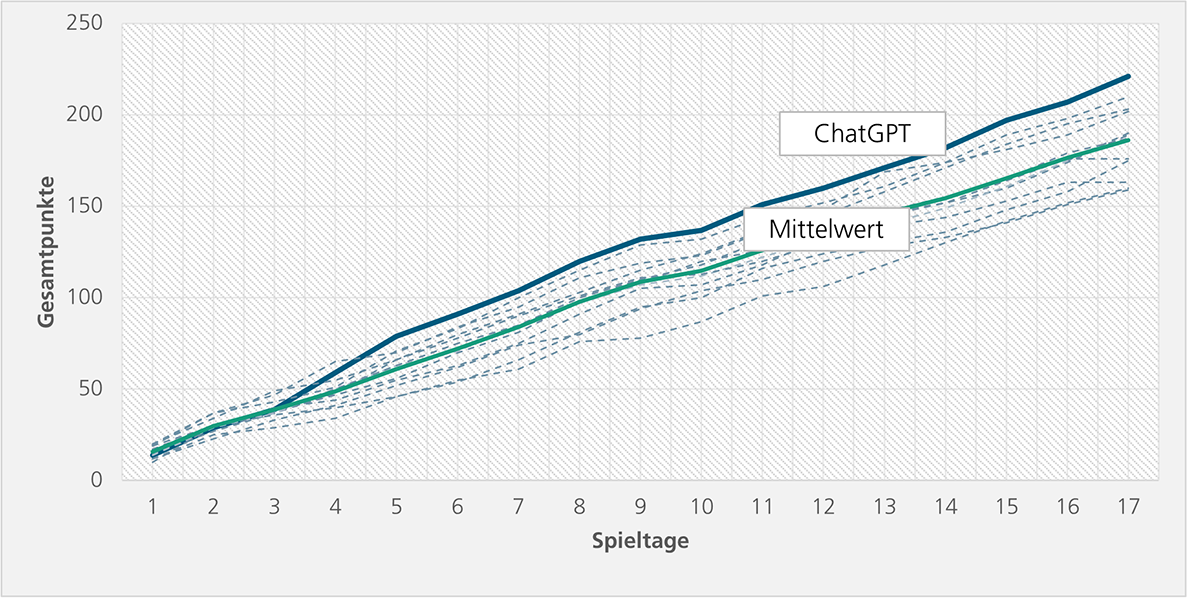
Seit dem sechsten Spieltag hatte ChatGPT den ersten Platz durchgängig verteidigt.
Insgesamt gab ChatGPT 153 Tipps ab, davon 24 auf »Unentschieden«. Bei den übrigen 129 setzte es 71-mal auf den Sieg der Mannschaft mit Heimvorteil und bei 58 auf die Gäste.
Man könnte vermuten, dass ChatGPT schlicht der Wettquote folgte, mit verschiedenen Faktoren als Grundlage für das konkrete Torverhältnis. Nach der ersten Saisonhälfte wurde jedoch klar, dass weitere Faktoren im Spiel waren. So setzte ChatGPT in sechs Fällen sogar deutlich gegen die Wettquote – und davon viermal mit der richtigen Tendenz.
Manchmal gewinnt der Bessere: ChatGPT wird Tippkönig
Mit beinahe ungebrochener Dominanz knüpfte ChatGPT Tag für Tag an die bisherigen Erfolge an – und errang letztlich die Krone des Tippspiels:

Insgesamt trug ChatGPT zehn Tagessiege davon, erhielt also die meisten Punkte an einem Spieltag, und erzielte an 75 Prozent der Spieltage mehr Punkte als der Durchschnitt.
Da ich die Teilnahmegebühr vorgestreckt hatte, stand ChatGPT nun auch der Preis für den ersten Platz zu: ein Trikot des Lieblingsvereins. Erfolgsfan durch und durch entschied sich ChatGPT für ein Trikot von Bayer Leverkusen. Wie genau wir das feierlich überreichen können, bleibt noch offen.
Spannend bleibt auch, ob ChatGPT zur Europameisterschaft an diesen Erfolg anknüpfen kann.
Nach dem Spiel ist vor dem Spiel: Was hat das nun alles mit Technologiemanagement zu tun?
Die Frage »Wie?«: Eine wichtige Fähigkeit, die ich während der gesamten Saison stetig weiterentwickelt habe, ist das »Bedienen« von ChatGPT, also das Bereitstellen zusätzlicher Kontextinformationen und die Eingabe der »Prompts«. Dabei gilt es den Input sinnvoll auszuwählen und den erwarteten Output klar zu beschreiben.
Kontextinformationen: ChatGPT hatte nur Zugriff zu zeitversetzten Informationen und damit unter Anderem nicht auf die aktuellen Spielpaarungen, Wettquoten oder Tabellen. Diese stellte ich bereit. Tatsächlich könnte man aber noch unzählige weitere Datenpunkte einbinden, beispielsweise die Spielerraster, den aktuellen Verlauf der Champions League, verletzungsbedingte Ausfälle oder die Startaufstellung. Es stellt sich für die Nutzung von Sprachmodellen die allgemeine Frage: »Welchen Input sollte ich liefern?« Die Antwort auf diese Frage erfordert einerseits ein Aufwand-Nutzen-Kalkül und andererseits ein grundlegendes Verständnis der Aufgabe selbst. Dass für einen Fußball-Tipp Wettquoten nützliche Informationen sein können ist trivial, doch längst nicht bei allen Aufgaben liegt der erforderliche Input so deutlich auf der Hand.
Prompts: Über Prompt-Engineering gibt es bereits zahllose Beiträge. Ich möchte an dieser Stelle nur einen Punkt nennen, der meiner Meinung nach immer etwas zu kurz kommt: die klare und durchdachte Definition des tatsächlich gewünschten Outputs. Als Menschen sind wir es gewöhnt, viele relevante Aspekte einer Frage zu berücksichtigen, ohne dass diese explizit ausformuliert sein müssen. Die Bequemlichkeit verleitet uns bei ChatGPT, den Output, den wir uns wünschen, zu schwammig einzufordern. So schrieb ich zu Beginn: »Ich hätte gerne Prognosen für die Bundesliga«. Was ich aber eigentlich wollte – und zuletzt auch so formulierte: »Gib mir quantifizierte Prognosen für die Ergebnisse des Spieltages. Ziel ist die Maximierung der Punktezahl nach den Spielregeln«. Meist ist die Formulierung des geforderten Outputs nicht so einfach wie in diesem Beispiel. Gerade bei komplexeren Aufgaben bedarf es zunächst einer systematischen Ausarbeitung, welcher Output wie genau geliefert werden soll.
Die Frage »Wofür?«: Vor der Frage der Umsetzung steht die eigentlich noch viel wichtigere Frage, wofür generative KI überhaupt eingesetzt werden kann oder soll. ChatGPT ist nutzerfreundlich, leicht zugänglich und funktioniert auch ohne große Überlegung – es gilt lediglich Text einzugeben, beliebig durchdacht oder strukturiert. Fast gleichgültig, was man fragt oder vorgibt, das Sprachmodell liefert ein Ergebnis. Doch ist ein solches Sprachmodell wirklich dafür geeignet, verlässliche Prognosen abzugeben? Hatte ChatGPT vielleicht einfach nur Glück?
Technisch betrachtet setzt die Anwendung »nur« Sprachbausteine aneinander und führt ohne Verknüpfung mit anderen Modellen weder multivariate Regressionen durch, noch entwickelt es im Hintergrund komplexe Simulationsmodelle – zumindest nicht explizit als solche formuliert.
Das lässt sich auch über das Tippspiel hinaus verallgemeinern. Es stellt sich für beliebige Anwendungsfälle die Frage: Was kann oder macht das Modell eigentlich? Und ist dieser Mechanismus für die Aufgabe, die ich damit lösen möchte, wirklich geeignet? Bekomme ich wertvolle Ergebnisse oder erhalte ich nur plausibel klingende Sprachfragmente? Die Antworten auf diese Fragen sind in keiner Weise trivial:
Überlegungen zur Eignung generativer KI für eine Aufgabe im Vorhinein sind schwierig, da die Mechanismen und Entscheidungsparameter eines neuronalen Netzes im Hintergrund kaum mehr nachvollziehbar und auch die Eignung der Trainingsdaten häufig nicht gesichert ist. Wieder anhand unseres Beispiels: Was wäre, wenn das Sprachmodell vor allem anhand von Texten aus Fan-Foren des FC Bayern München trainiert wurde?
Die Überprüfung der Eignung im Nachgang ist auch nicht leicht: Wir müssten eine Vielzahl von Tippspielen über eine Vielzahl von Saisons durchführen, um empirisch bewerten zu können, wie verlässlich die Prognosen wirklich sind. Besonders herausfordernd wird eine solche Bewertung dann, wenn die Qualität der Ergebnisse schwer zu messen oder zu quantifizieren ist.
»Fußball ist deshalb spannend, weil niemand weiß, wie das Spiel ausgeht.«
Das sagte einst der legendäre Sepp Herberger – über generative KI, auch im Technologiemanagement, kann man heute dasselbe sagen: Das Thema ist hochspannend und niemand weiß wirklich, wie es ausgehen wird. Im Technologiemanagement stellen wir uns deshalb die schon diskutierten Fragen: Für welche Aufgaben können und sollten wir generative KI einsetzen? In der Technologiefrüherkennung oder -planung? Bei Technologiebewertungen oder für die Ausarbeitung von Strategien? Und wenn der Einsatz sinnvoll erscheint, wie genau sollte die Umsetzung erfolgen? Welcher Input ist erforderlich und welcher Output sollte wie gefordert werden?
Diese Fragen zu erforschen ist unser Thema: Wir beleuchten generative KI im Technologiemanagement, um geeignete Anwendungsfälle zu identifizieren und die Umsetzung zu optimieren. Wenn Sie das Thema genauso spannend finden wie wir und für sich die perfekte Aufstellung finden wollen, dann kommen Sie gerne auf mich oder unser Team zu – wir freuen uns auf den Austausch.