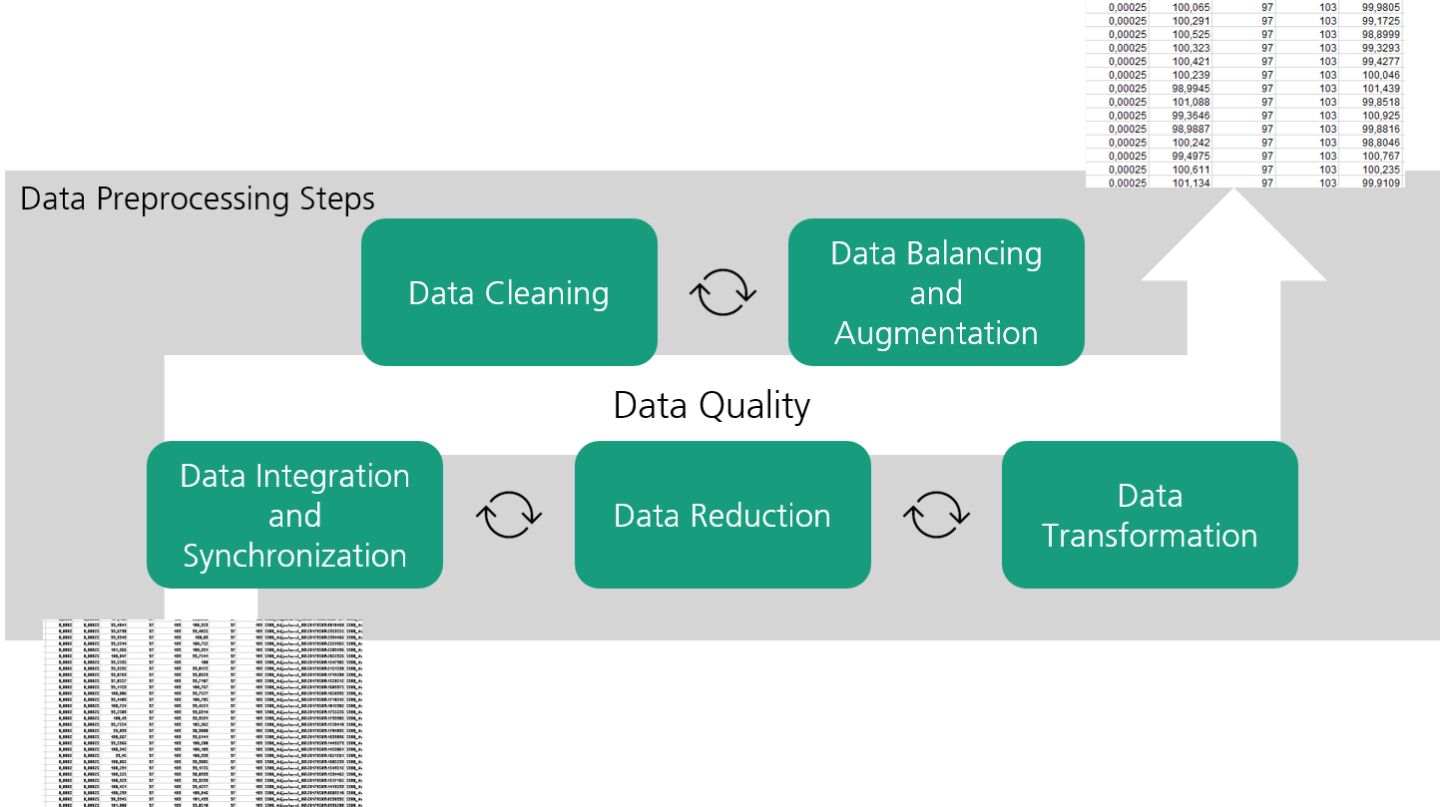
Data preprocessing in several methodical steps
In order to convert data into a usable state and ensure the highest possible data quality for subsequent analyses, the Fraunhofer IPT has developed a pipeline for standardized data preprocessing: The Data Preprocessing Pipeline provides methods for a structured preprocessing of data in several methodical steps:
- Integration (e.g. Join and Union)
- Cleaning (e.g. Outlier Detection and Imputation)
- Augmentation (e.g. Interpolation and Feature Engineering)
- Reduction (z.B. Principal Component Analysis and Feature Extraction)
- Transformation (e.g. One-hot Encoding and Discretization)
The result of the data preprocessing is a prepared data set that can be used for statistical data analysis and machine learning. Due to the current developments in Automated Machine Learning (AutoML), intensive work is being done on the automation of data preprocessing. The Fraunhofer IPT is investigating the use of automated data preprocessing in the production context in order to accelerate the manual data preprocessing currently being used and to relieve data scientists of these monotonous tasks in future.
Our range of services
- Data quality check to assess the data quality of companies and roadmapping to improve data quality
- Implementation of a reusable data preprocessing pipeline for the standardized preparation of data in the company
- Data preprocessing seminar for empowering employees to develop a company-specific data preprocessing pipeline
 Fraunhofer Institute for Production Technology IPT
Fraunhofer Institute for Production Technology IPT